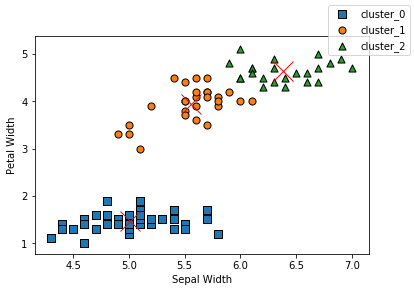
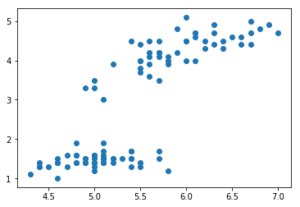
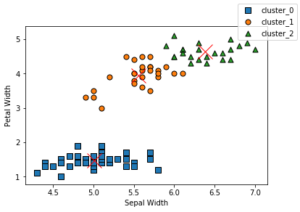
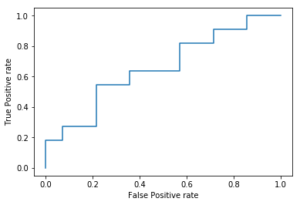
# 決定木のハイパーパラメータである層深さの最適化
from sklearn.datasets import load_iris
from sklearn.model_selection import GridSearchCV # グリッドサーチ
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# Irisデータをセットする
iris = load_iris()
iris.keys() # dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
X = iris.data
y = iris.target
# 訓練用データ と 検証用データに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# 決定木モデルを作成す
tree = DecisionTreeClassifier()
'''
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
'''
# グリッドサーチ用のハイパーパラメータのリストをディクショナリで定義する
param_grid = {'max_depth': [3,4,5]}
# 層化 10分割 交差検証を行う
#(引数としてインスタンス化された決定木モデルをここで入れる)
cv = GridSearchCV(tree, param_grid=param_grid, cv=10)
cv.fit(X_train, y_train)
'''
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best'),
fit_params=None, iid='warn', n_jobs=None,
param_grid={'max_depth': [3, 4, 5]}, pre_dispatch='2*n_jobs',
refit=True, return_train_score='warn', scoring=None, verbose=0)
'''
# 最適なパラメータを出力する
cv.best_params_ # {'max_depth': 3}
'''
param_gridを層深さに指定したので、best_prams_も層深さで出力される
'''
# 最適なモデルを確認する
cv.best_estimator_
'''
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=5,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
'''
# 最適なモデルで予測する
y_predicted = cv.predict(X_test)
y_predicted
'''
array([2, 1, 0, 2, 0, 2, 0, 1, 1, 1, 2, 1, 1, 1, 1, 0, 1, 1, 0, 0, 2, 1,
0, 0, 2, 0, 0, 1, 1, 0, 2, 1, 0, 2, 2, 1, 0, 2, 1, 1, 2, 0, 2, 0,
0])
'''
y_true = y_predicted == y_test
y_true
'''
array([ True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, False, True, True, True, True, True, True, True])
'''