k-means法
教師なしクラスタリングということで k-means法を試してみました。
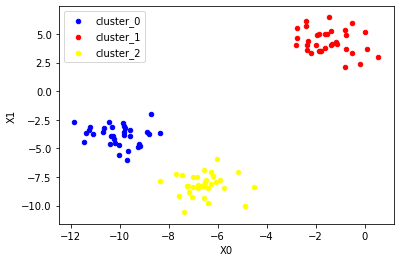
ブロブデータでやってみる
データセットからブロブを呼び出します。

このブロブをk-means法を使って分類します。
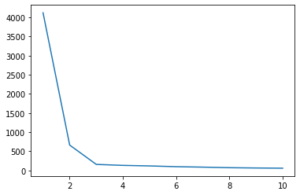
k-meansの条件としてクラスタの数を指定しますが、下記のようなエルボ法を使ってベストなクラスタ数を決定します。今回は3です。
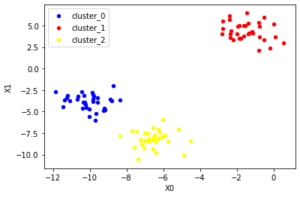
k-meansの結果がこれです。うまく行っています。
顧客データでやってみる
エルボ法でベストなクラスタ数を見つけておきます。
5にしましょうか。
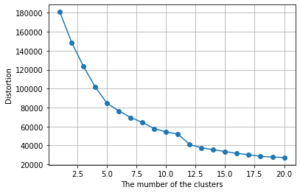
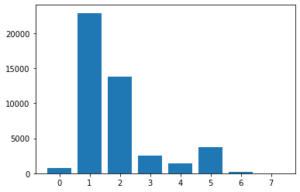
クラスタ数5の結果です。
1と3に固まっていますね。
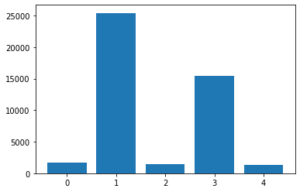
ちなみにk-means デフォルトクラスタ数8でやってみました。
さっきのクラスタ3は下の2,3に分割されてしまっていると考えます。
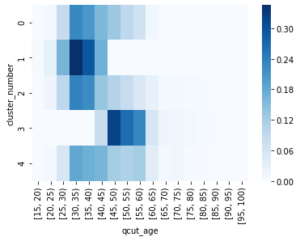
クラスタ数5に戻って、結果のヒートマップを確認します。
年齢層でみると、クラスタ1は30-35歳、クラスタ3は45-50歳というように離れていることがわかります。
次は職業です。クラスタ数1と3は大きな差がないので、今回のクラスタリング結果に対して職業の寄与度は低いのでしょう。
