深層強化学習をやっていこう
今日から強化学習AIの道場 gymnasiumを使って深層決定論的方策勾配DDPGを試していきたいと思います。
環境
- windows10 python3.7.9
- メモリ8GB
- core i7 7700
- RTX3070Ti
- visual studio code/
- python 3.7.9
- venv 仮想環境
モジュール
多分もっと増えていきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
Package Version -------------------- ------- absl-py 1.4.0 cloudpickle 2.2.1 Farama-Notifications 0.0.4 glfw 2.5.9 gym 0.26.2 gym-notices 0.0.8 gymnasium 0.28.1 imageio 2.28.1 importlib-metadata 6.1.0 jax-jumpy 1.0.0 mujoco 2.3.5 numpy 1.21.6 Pillow 9.5.0 pip 23.1.2 pygame 2.3.0 PyOpenGL 3.1.6 setuptools 47.1.0 swig 4.1.1 typing_extensions 4.5.0 zipp 3.15.0 |
とりあえず学習なしで動かしてみる。
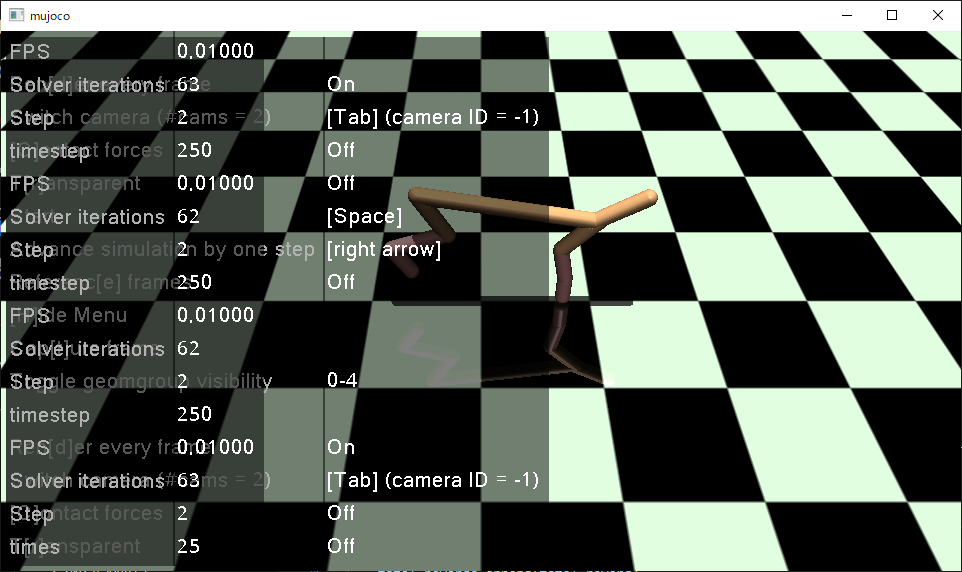
gymnasiumの HalfCheetah-v4 半分チーター(動物)?のエージェントモデルを動かして描画するところまでやっていきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import gymnasium as gym import time env = gym.make("HalfCheetah-v4", render_mode= 'human') EPISODES = 2 DELAY_TIME = 0.00 # sec total_rewards = [] for eposode in range(EPISODES): obs = env.reset() print('observation_space : ', env.observation_space) print('obs :', obs) reward = 0 total_reward = 0 done = False for j in range(100): env.render() action = env.action_space.sample() print('action_space : ', env.action_space) print('action : ', action) next_state, reward, done, _, info = env.step(action) print('next_state, reward, done, _, info :', next_state, reward, done, _, info) obs = next_state total_reward += reward time.sleep(DELAY_TIME) print('total_reward : ', total_reward) total_rewards.append(total_reward) print('total_rewards : ', total_rewards) env.close() # 空なんですけど・・・ print('script is done.') # https://gymnasium.farama.org/ |
結果
エピソード数1、繰り返しステップ数1に変更した場合です。
観察空間は17個 マイナス無限からプラス無限までの連続値です。
行動空間は6個 -1から+1までの連続値です。
最後にscript is done.と出力されているので、特に問題なさそうです。
が・・・
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
observation_space : Box(-inf, inf, (17,), float64) obs : (array([ 0.02485869, -0.08434862, -0.04511497, -0.08579491, 0.00076974, -0.05903329, 0.09622602, -0.0461476 , 0.07756127, 0.11203682, 0.15562385, -0.22147787, 0.01759578, 0.07849912, -0.04187814, 0.06876929, 0.00292594]), {}) action_space : Box(-1.0, 1.0, (6,), float32) action : [-0.3660471 0.07370865 -0.33536777 -0.00359232 -0.06751072 -0.27815822] next_state, reward, done, _, info : [ 7.62149187e-03 -8.01887540e-02 -1.37769448e-01 3.27668373e-02 -1.22453461e-01 -1.61535935e-02 7.06252930e-04 -9.38258318e-02 -2.00889555e-02 -5.68076861e-01 1.14528769e-01 -2.20827479e+00 2.45804234e+00 -3.00804250e+00 1.02273244e+00 -2.36049060e+00 -1.37703787e+00] -0.03053368795621509 False False {'x_position': -0.013300085731865507, 'x_velocity': 0.0028500719000089728, 'reward_run': 0.0028500719000089728, 'reward_ctrl': -0.03338375985622406} total_reward : -0.03053368795621509 total_rewards : [-0.03053368795621509] script is done. |
エラー発生
スクリプト自体は最後の行まで問題なく script is doneと表示されていますが、
なんか出てます。
|
1 2 3 4 5 6 7 8 9 10 |
Exception ignored in: <function WindowViewer.__del__ at 0x0000025F7AC781F8> Traceback (most recent call last): File "C:\dev\gym_test\gym_env\lib\site-packages\gymnasium\envs\mujoco\mujoco_rendering.py", line 335, in __del__ File "C:\dev\gym_test\gym_env\lib\site-packages\gymnasium\envs\mujoco\mujoco_rendering.py", line 330, in free File "C:\dev\gym_test\gym_env\lib\site-packages\glfw\__init__.py", line 1278, in destroy_window File "C:\dev\gym_test\gym_env\lib\site-packages\glfw\__init__.py", line 691, in errcheck File "C:\dev\gym_test\gym_env\lib\site-packages\glfw\__init__.py", line 70, in _reraise File "C:\dev\gym_test\gym_env\lib\site-packages\glfw\__init__.py", line 670, in callback_wrapper File "C:\dev\gym_test\gym_env\lib\site-packages\glfw\__init__.py", line 916, in _handle_glfw_errors TypeError: 'NoneType' object is not callable |
chatGPTによると
|
1 2 3 4 5 6 7 8 9 10 |
このエラーは、プログラムの実行中に、WindowViewerオブジェクトが破棄されるときに発生しました。WindowViewerオブジェクトは、Mujoco環境をレンダリングするために使用されます。Mujocoのレンダリングに関する問題が発生したため、このエラーが発生した可能性があります。 このエラーは、通常、単に無視しても安全です。ただし、エラーが頻繁に発生する場合、Mujoco環境のレンダリングに問題があるため、問題を解決する必要があります。 問題を解決するためには、次のことを試すことができます。 システムのグラフィックドライバを更新します。 仮想環境を再インストールします。 レンダリング設定を変更します。 Mujocoのバージョンをアップグレードすることも、問題を解決する可能性があります。 |
と言われますが、どうにもならないので無視しました。
env.close()が本来こういったエラーが出ないようにするはずですが、メソドの中身を見ると、説明書きだけでコードは空でした・・・
次回
DDPGをちょっとずつ作っていきます。