こんにちはKeita_Nakamoriです。
今日はブレストキャンサーデータを良く眺めてみようと思います。
データをロードしてキーを確認しましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#ロードブレストキャンサーデータを眺める from sklearn.datasets import load_breast_cancer #ロードブレストキャンサーデータのインスタンスを作成 cancer_data=load_breast_cancer() #キーを確認する cancer_data.keys() """ dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names']) """ |
キーを指定してデータの内容を確認しましょう
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# 内容を確認する cancer_data["data"].shape #(569, 30) 30次元のベクトルが569データある cancer_data["target"].shape#(569,) 1次元の0と1の羅列が569データある cancer_data["feature_names"] """様々な特徴量 array(['mean radius', 'mean texture', 'mean perimeter', 'mean area', 'mean smoothness', 'mean compactness', 'mean concavity', 'mean concave points', 'mean symmetry', 'mean fractal dimension', 'radius error', 'texture error', 'perimeter error', 'area error', 'smoothness error', 'compactness error', 'concavity error', 'concave points error', 'symmetry error', 'fractal dimension error', 'worst radius', 'worst texture', 'worst perimeter', 'worst area', 'worst smoothness', 'worst compactness', 'worst concavity', 'worst concave points', 'worst symmetry', 'worst fractal dimension'], dtype='<U23') """ cancer_data["target_names"] """ array(['malignant', 'benign'], dtype='<U9') malignant は悪性 benign は良性 を意味する """ |
おまけ
np.bincount()を使うと 順番に[0の数 , 1の数 , 2の数,・・・]というようなベクトルが得られる
|
1 2 3 4 5 6 7 8 9 10 11 |
# ターゲットの 0の数(悪性)と1の数(良性)をカウントする import numpy as np np.bincount(cancer_data["target"]) """ array([212, 357], dtype=int64) 悪性=212 個 良性=357 個 """ |
勢い余って、KNNをやってしまおう
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# ==== 勢い余って、KNNをやってしまおう ==== %matplotlib inline from sklearn.model_selection import train_test_split import numpy as np import pandas as pd import matplotlib.pyplot as plt import mglearn #入力データと出力データを定義する X=cancer_data["data"] # as input y=cancer_data["target"] # as output #訓練用データと検証用データに分ける X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0) from sklearn.neighbors import KNeighborsClassifier knn=KNeighborsClassifier(n_neighbors=1) #機械学習モデルを作成する knn.fit(X_train,y_train) """ KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=1, p=2, weights='uniform') """ #スコアを確認する knn.score(X_test,y_test) """ 0.916083916083916 """ |
おわりに
ということで、たったこれだけで、92%の正解率が得られました。
これは、データがしっかり整っているからできることです。
実際に自分自身の課題に対して機械学習を適用しようとすると、データを収集してきれいに整えることにエネルギーを費やすのだと思います。
番外:データフレームとスキャッターマトリクスを眺めてみる
データ数と特徴量が多すぎて、すごいことになっています。
|
1 2 3 4 5 |
#データフレーム化してデータを眺めてみる columns=cancer_data["feature_names"] #データフレームの列名を定義df=pd.DataFrame(X_train,columns=columns) df=pd.DataFrame(X_train,columns=columns) df[:5] |
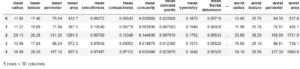
|
1 |
grr=pd.plotting.scatter_matrix(df,c=y_train,figsize=(20,20),marker="o",hist_kwds={"bins":1},s=100,alpha=0.5,cmap=mglearn.cm3) |
うわ~~~~~ (*´﹃`*)
