Contents
方策勾配法にチャレンジしました。
オライリージャパンの ゼロから作るDeep Learning 4 強化学習編を参考にしながら作成しました。
本書ではニューラルネットワークをdezeroというオリジナルのフレームワークで記述されておりましたが、もっと汎用的に使えるように独自にpytorchへ変更しました。悩みながら2日かけてなんとか動いてくれました。
必要なモジュールをインポート
|
1 2 3 4 5 6 7 8 9 10 |
import gym import torch import torch.nn as nn import torch.optim as optim import numpy as np import matplotlib.pyplot as plt import seaborn as sns from torchvision import datasets, transforms from torch.utils.data import DataLoader %matplotlib inline |
GPUを利用する
|
1 2 3 |
# GPUが使えるかどうか確認する device = "cuda" if torch.cuda.is_available() else 'cpu' device |
方策クラスの定義
|
1 2 3 4 5 6 7 8 9 10 11 12 |
class Policy(nn.Module): def __init__(self, action_size): super().__init__() self.classifier = nn.Sequential( nn.Linear(4, 128), # observationの変数は4つを想定する:位置、傾き角度、速度、角速度 nn.ReLU(inplace=True),# inplace:元の配列をReLUによって書き換える:元の配列を保持しないのでメモリーが節約できる nn.Linear(128, action_size), nn.Softmax() ) def forward(self, x): action_prob = self.classifier(x) return action_prob |
エージェントクラスの定義
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
class Agent: def __init__(self): self.gamma = 0.99 self.lr = 0.001 self.action_size = 2 self.memory = []# トラジェクトを入れていくメモリー self.pi = Policy(self.action_size) # AgentがPolicyを含有することにする。 self.optimizer = optim.Adam(self.pi.parameters(), self.lr) def get_action(self, state): state = state[np.newaxis,:] # バッチの軸を新規追加 state = torch.from_numpy(state) probs = self.pi(state) #print(probs) # tensor([[0.5537, 0.4463]], grad_fn=<SoftmaxBackward0>) probs = probs[0] # tensorで[[ ]]の形になっているので[ ]を一つ外す操作 #print(probs) #tensor([0.5537, 0.4463], grad_fn=<SelectBackward0>) action = np.random.choice(len(probs), p=probs.data.numpy()) # numpy形式にしないと受け付けない return action, probs[action] # 選択した行動と、その行動をとる確率を返す def add(self, reward, prob): data = (reward, prob) self.memory.append(data)# 報酬とその行動をとる確率をデータとしてメモリに保存する。 def update(self): #self.pi.cleargrads() # ボツ self.optimizer.zero_grad() # 勾配の初期化 # 収益 損失の初期化 G, loss = 0, 0 # 収益の計算:メモリを逆から読み込む。←ゴールに近いところから計算する for reward, prob in reversed(self.memory): G = reward + self.gamma * G # これで 収益G = R0 +γR1 +γγR2 +γγγR3 が得られる。 # 損失の計算 for reward, prob in self.memory: loss += - G * torch.log(prob) # 方策π(At|St)はprobのこと [左に行く確率,右に行く確率 ] # ボツ loss.backward() # ボツ self.optimizer.update # 目的関数の勾配を求める loss.backward(retain_graph=True) # 誤差 逆伝搬計算 agent.optimizer.step() # オプティマイザによるパラメータ更新 self.memory = [] # メモリーをリセット |
メインスクリプト
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
episodes = 3000 env = gym.make('CartPole-v0') agent = Agent() reward_history = [] for episode in range(episodes): state = env.reset() # 初期化 done = False # 初期化 total_reward = 0 # 初期化 while not done: # その状態のときに選択した行動と、その行動をとる確率を返す action, prob = agent.get_action(state) #print('agent.get_action(state) ==>episode, state, action, prob : ', episode, state, action, prob) # をの行動をとった時に、次の状態 報酬 終了フラグ そしてよくわからないがinfoを得る next_state, reward, done, info = env.step(action) #print('agent.get_action(state) : ', next_state, reward, done, info, total_reward) # 結果、報酬とその行動をとる確率をデータとしてメモリに保存する。 agent.add(reward, prob) print('agent.add(reward, prob) : ', reward, prob) state = next_state # 報酬を収益としてまとめる total_reward += reward # 継続できた時間 # done=Trueでゴールしたとき whileを抜ける agent.update() # エピソード毎の生き残り時間を保存しておく。 reward_history.append(total_reward) |
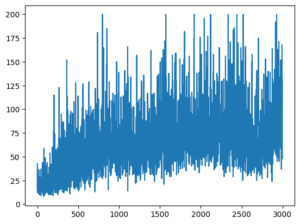
結果グラフ
|
1 |
plt.plot(reward_history) |
The following two tabs change content below.

Keita N
最新記事 by Keita N (全て見る)
- 2024/1/13 ビットコインETFの取引開始:新たな時代の幕開け - 2024年1月13日
- 2024/1/5 日本ビジネスにおける変革の必要性とその方向性 - 2024年1月6日
- 2024/1/3 アメリカ債権ETFの見通しと最新動向 - 2024年1月3日