多層パーセプトロンで近似してみます

モジュール
|
1 2 3 4 5 6 7 8 9 |
import torch import torch.nn as nn import torch.optim as optim import numpy as np import matplotlib.pyplot as plt import seaborn as sns from torchvision import datasets, transforms from torch.utils.data import DataLoader %matplotlib inline |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
# GPUが使えるかどうか確認する device = "cuda" if torch.cuda.is_available() else 'cpu' device 'cuda' # データを呼び出す transform = transforms.Compose([transforms.ToTensor()]) # 画像をtensorに変換する。channel firstへ変換。0-1へ変換。 train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform) train_dataset Dataset MNIST Number of datapoints: 60000 Root location: ./data Split: Train StandardTransform Transform: Compose( ToTensor() ) # バッチサイズを定義する (バッチサイズと言ったら ミニバッチのサイズのことを指す。データ全数のことではない) num_batches = 100 # データセットからバッチサイズ分を抽出する。 train_dataloader = DataLoader(train_dataset, batch_size=num_batches, shuffle=True) train_iter = iter(train_dataloader) imgs, labels = next(train_iter) imgs, labels imgs.size() # torch.Size([100, 1, 28, 28]) チャネルファースト100データ,モノクロ1行,(縦28x横28) torch.Size([100, 1, 28, 28]) # 教師データの確認 labels tensor([1, 7, 9, 9, 6, 3, 4, 0, 2, 8, 4, 3, 4, 1, 5, 7, 6, 6, 8, 8, 6, 7, 9, 3, 6, 2, 7, 3, 2, 6, 5, 2, 8, 7, 0, 4, 1, 4, 6, 5, 6, 9, 8, 9, 8, 3, 1, 2, 4, 6, 9, 4, 8, 1, 7, 4, 7, 4, 5, 7, 8, 5, 4, 2, 5, 1, 8, 3, 6, 8, 1, 8, 9, 9, 6, 6, 7, 4, 8, 8, 1, 3, 7, 6, 4, 5, 5, 9, 4, 1, 0, 5, 6, 8, 6, 9, 3, 5, 3, 2]) #イメージデータ 0番目の確認 img = imgs[0] # torch.Size([0番目, 1, 28, 28]) チャネルファースト100データ,モノクロ1行,(縦28x横28) print(img.size()) # torch.Size([1, 28, 28]) img torch.Size([1, 28, 28]) tensor([[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000], [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]]) # permuteでチャネルファーストをやめて 縦x横xch へからを入れ替える img_permute = img.permute(1,2,0) print(img_permute.size()) # torch.Size([28, 28, 1]) img_permute torch.Size([28, 28, 1]) tensor([[[0.0000], [0.0000], [0.0000], [0.0000], [0.0000], [0.0000], |
|
1 2 3 4 5 |
# sns.heatmapで描画 numpy化が必要 sns.heatmap(img_permute.numpy()[:,:,0]) # 教師データ print(labels[0]) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
class MLP(nn.Module): def __init__(self): super().__init__() self.classifier = nn.Sequential( nn.Linear(28*28, 400), nn.ReLU(inplace=True),# inplace:元の配列をReLUによって書き換える:元の配列を保持しないのでメモリーが節約できる nn.Linear(400, 200), nn.ReLU(inplace=True), nn.Linear(200, 100), nn.ReLU(inplace=True), nn.Linear(100, 10) ) def forward(self, x): output = self.classifier(x) return output |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
#MLPのインスタンスを作成する model = MLP() # modelをGPU上に送る model.to(device) MLP( (classifier): Sequential( (0): Linear(in_features=784, out_features=400, bias=True) (1): ReLU(inplace=True) (2): Linear(in_features=400, out_features=200, bias=True) (3): ReLU(inplace=True) (4): Linear(in_features=200, out_features=100, bias=True) (5): ReLU(inplace=True) (6): Linear(in_features=100, out_features=10, bias=True) ) ) criterion = nn.CrossEntropyLoss() # 多クラス分類 optimizer = optim.Adam(model.parameters(), lr=0.001) # オプティマイザー """ バッチ学習:全データを一気に学習する ミニバッチ学習:全データから無作為に抽出して、複数回に分けて学習する """ num_epochs = 10 # 何回繰り返すか losses = [] #損失 accs = [] #精度 for epoch in range(num_epochs): running_loss = 0.0 # 損失の初期化 running_acc = 0.0 # 精度の初期化 for imgs, labels in train_dataloader: imgs = imgs.view(num_batches, -1) # 1次元ベクトルへ変換 imgs = imgs.to(device) # GPU上へ送る labels =labels.to(device) # GPU上へ送る optimizer.zero_grad() # 勾配の初期化 output = model(imgs) # モデル順伝播計算 loss = criterion(output, labels) running_loss += loss.item() pred = torch.argmax(output, dim=1) # dim=0はバッチ方向 dim=1 は分類方向 running_acc += torch.mean(pred.eq(labels).float()) loss.backward() # 誤差 逆伝搬計算 optimizer.step() # オプティマイザによるパラメータ更新 running_loss /= len(train_dataloader) running_acc /= len(train_dataloader) losses.append(running_loss) accs.append(running_acc) print(f'epoch : {epoch}, loss {running_loss}: ,acc : {running_acc}') |
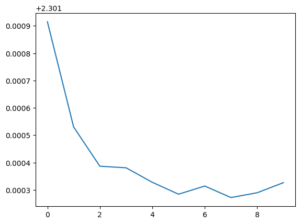
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 学習済みパラメーターを抜き出す params = model.state_dict() # パラメータをファイルに保存する torch.save(params, 'model.prm') # パラメータをファイルから読み込む param_load = torch.load('model.prm') param_load OrderedDict([('classifier.0.weight', tensor([[-3.5617e-02, 8.9706e-03, 3.4050e-02, ..., -9.2121e-03, -6.5885e-05, -1.0760e-02], [ 2.0486e-02, -3.1989e-02, 4.9619e-04, ..., -1.1030e-02, 3.4729e-02, -2.9047e-02], [-5.6085e-03, -2.2364e-02, 4.2380e-03, ..., -5.4451e-03, 3.1651e-02, 3.1243e-02], ..., [ 3.4697e-02, -1.2696e-02, -1.9370e-02, ..., -1.3790e-02, -2.0770e-02, -2.9269e-02], [-2.5984e-02, -6.8645e-03, -3.7604e-03, ..., -1.8618e-02, -2.4756e-02, 1.7510e-02], [-1.2803e-02, 3.7466e-03, -2.7087e-02, ..., -1.4499e-02, -1.8533e-02, 1.8600e-02]], device='cuda:0')), ('classifier.0.bias', tensor([ 2.5952e-02, -1.7248e-02, -4.3149e-02, -1.6513e-02, 1.0530e-02, -1.2782e-02, -1.2642e-02, -3.1505e-02, 2.4053e-02, -2.4963e-02, -7.3092e-03, -4.1888e-02, -5.4823e-03, 1.1824e-02, -6.8225e-02, 1.6625e-02, -1.6976e-02, -1.2219e-02, 1.3059e-02, 2.1564e-02, -1.3850e-02, -3.6530e-02, -8.9879e-03, -1.2830e-02, -8.4952e-03, 1.0740e-02, 1.5189e-02, 2.5338e-02, -2.3679e-02, -1.6828e-02, |
|
1 2 3 4 5 |
# 学習済みパラメーターを抜き出す params = model.state_dict() # パラメータをファイルに保存する torch.save(params, 'model.prm') |
#読み込んだパラメータがちゃんと型にあっているかどうか
model.load_state_dict(param_load)
The following two tabs change content below.

Keita N
最新記事 by Keita N (全て見る)
- 2024/1/13 ビットコインETFの取引開始:新たな時代の幕開け - 2024年1月13日
- 2024/1/5 日本ビジネスにおける変革の必要性とその方向性 - 2024年1月6日
- 2024/1/3 アメリカ債権ETFの見通しと最新動向 - 2024年1月3日