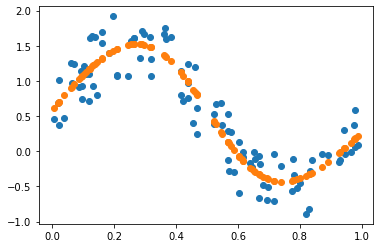
dezeroでニューラルネットワークを使った回帰をやってみる2
dezeroに搭載されている、model, optimizer, MSEをフル活用したバージョンです。
結果は前回と同様によく回帰できていますね。
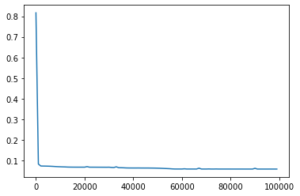
損失の減り方がとても早いです。今回はAdamを使っているのでうまく昨日しているようです。悩んだらAdamは間違ってないようです。
スクリプトはこちらに貼っておきます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 |
# ニューラルネットワークで回帰(レイヤ モデル 最適化手法) import numpy as np from dezero import Variable from dezero import Model import dezero.layers as L import dezero.functions as F from dezero import optimizers # データサンプルを生成 np.random.seed(0) x = np.random.rand(100, 1) # 行x列 y = np.sin(2*np.pi*x)+np.random.rand(100,1) plt.plot(x,y,'o') # 学習 lr = 0.1 iters = 100000 loss_list = [] iters_list = [] # モデルをdezeroから継承する class TwoLayerNet(Model): def __init__(self, hidden_size, out_size): super().__init__() self.l1 = L.Linear(hidden_size) self.l2 = L.Linear(out_size) def forward(self, x): y = F.sigmoid(self.l1(x)) y = self.l2(y) return y # モデルのインスタンスを作成 model = TwoLayerNet(10, 1)#隠れ層のサイズ, 出力層のサイズ # オプティマイザを生成 #optimizer = optimizers.SGD(lr) # 最初にお世話になるSGD optimizer = optimizers.Adam(lr) # 悩んだらアダム optimizer.setup(model) # モデルのセットアップする 意味不明。 """ いらないくなった # dezero変数へ変換 x, y = Variable(x), Variable(y) # NNのパラメータの初期化 I, H, O = 1, 10, 1 W1 = Variable(0.01 * np.random.randn(I, H)) b1 = Variable(np.zeros(H)) W2 = Variable(0.01 * np.random.rand(H, O)) b2 = Variable(np.zeros(O)) # 推論:ニューラルネットワーク def predict(x): y = F.linear(x, W1, b1) y = F.sigmoid(y) y = F.linear(y, W2, b2) return y # 損失関数 def mean_squared_error(x0, x1): diff = x0 - x1 return F.sum(diff ** 2) / len(diff) """ for i in range(iters): # 予測 #y_pred = predict(x) y_pred = model.forward(x) # 実はもうある # 損失 #loss = mean_squared_error(y, y_pred) loss = F.mean_squared_error(y, y_pred) # 実はもうある """いらなくなった # 勾配初期化 W1.cleargrad() b1.cleargrad() W2.cleargrad() b2.cleargrad() """ # 勾配初期化 model.cleargrads() # 代わりにこれでいい # 損失勾配 loss.backward() # ここはかわらない """ いらなくなった # 勾配降下法によるパラメータ更新 W1.data -= lr * W1.grad.data b1.data -= lr * b1.grad.data W2.data -= lr * W2.grad.data b2.data -= lr * b2.grad.data """ """modelは使うが optimizerを使わないときはこのスクリプトを使う # パラメータ更新 for p in model.params(): # モデルパラムスに保存されてるっぽい p.data -= lr * p.grad.data # 勾配降下法 """ # オプティマイザを使って パラメータ更新 optimizer.update() if (i % 1000) == 0: # たまに損失の計算状況を出力をする print(i, loss.data) loss_list.append(loss.data) iters_list.append(i) # 結果表示 plt.plot(x.data, predict(x).data, 'o') plt.show() plt.plot(iters_list, loss_list) |
The following two tabs change content below.

Keita N
最新記事 by Keita N (全て見る)
- 2024/1/13 ビットコインETFの取引開始:新たな時代の幕開け - 2024年1月13日
- 2024/1/5 日本ビジネスにおける変革の必要性とその方向性 - 2024年1月6日
- 2024/1/3 アメリカ債権ETFの見通しと最新動向 - 2024年1月3日