chatGPTより提案されたニューラルネットワーク構造を導入してみます。
actorNNは隠れ層ノードを64から256に増やしました。
criticNNも隠れ層ノードを64から256に増やしました。
actorNNの活性化関数はrelu, relu,tanhで出力のまま変わらず。
criticNnの活性化関数はrelu,reluで最終層は活性化関数なしで出力。こちらも変更なしです。
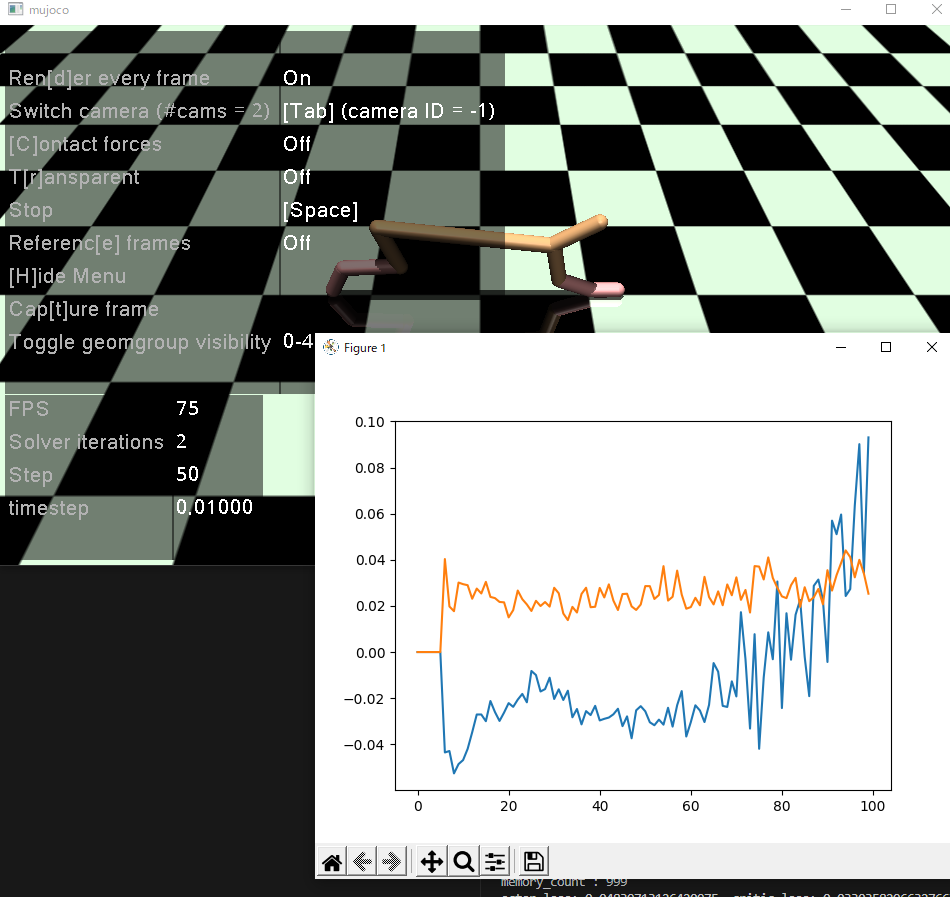
基本構造は悪くなかったようです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
# 6.ActorNNクラスを新規作成する class ActorNN(nn.Module): def __init__(self, alpha=0.000025, n_obs_space=17, n_action_space=6, layer1_size=256, layer2_size=256, batch_size=64): #print('ActorNN.__init__ is working.') super(ActorNN, self).__init__() self.fc1 = nn.Linear(n_obs_space, layer1_size) self.fc2 = nn.Linear(layer1_size, layer2_size) self.fc3 = nn.Linear(layer2_size, n_action_space) #26.最適化処理としてアダムを設定する self.optimizer = optim.Adam(self.parameters(), lr=alpha) def forward(self, obs): #print('AgetDDPG.ActorNN.forward is working') #print('====ここまではOK1====') x = self.fc1(obs) x = F.relu(x) x = self.fc2(x) x = F.relu(x) x = self.fc3(x) mu = F.tanh(x) #print('action μ:', mu) #print('====ここまではOK2====') # 必要であればあとでノイズを入れる:action = mu + noize action = mu return action # 22.CriticNNクラスを新規作成する class CriticNN(nn.Module): def __init__(self, beta=0.000025, n_obs_space=17, n_action_space=6, layer1_size=256, layer2_size=256, batch_size=64): #print('CriticNN.__init__ is working.') super(CriticNN, self).__init__() # クリティックNNは観察空間+行動空間の2つを入力とする構造 input_dim = n_obs_space + n_action_space self.fc1 = nn.Linear(input_dim, layer1_size) self.fc2 = nn.Linear(layer1_size, layer2_size) self.fc3 = nn.Linear(layer2_size, 1) # 最後は1個で良い #27.最適化処理としてアダムを設定する self.optimizer = optim.Adam(self.parameters(), lr=beta) def forward(self, obs, action): input_data = T.cat([obs, action], dim=1) x = self.fc1(input_data) x = F.relu(x) x =self.fc2(x) x = F.relu(x) x = self.fc3(x) return x #一つの状態価値を出力する。 |
変わらず actor_lossesが上昇傾向にあります。
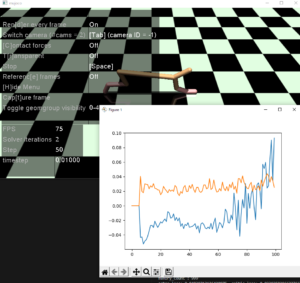
次は、ステップ数を10から50に増やしてみます。
前のめりを覚えたようで、たまにひっくり返ります。
しかし、actor_losses, critic_lossesは上昇傾向で変わらす。しかし、なんか前に行こうと頑張っているようには見えます。符号が逆になってないだろうか?
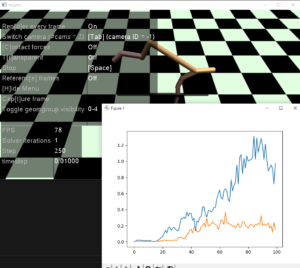
ここで行動にノイズを入れて環境の探索性を上げることで学習が良い方向に進むかやってみます。
DDPGにおけるOUActionNoiseクラスは、行動に対してオルナシュウ-ウーレンベック(Ornstein-Uhlenbeck)過程に基づくノイズを生成するために使用されるクラスです。このノイズは、環境の探索性を増加させるためにアクションに追加されます。
このクラスのインスタンス化時に、平均値(mu)、標準偏差(sigma)、タイムステップの幅(dt)、回帰係数(theta)、初期値(x0)を指定します。__call__メソッドは、ノイズを生成して返します。
DDPGの学習時には、Actorネットワークから生成されたアクションにOUActionNoiseクラスを適用してノイズを追加し、環境への探索性を高めます。これにより、探索と収束のトレードオフを実現し、より良いポリシーの探索を促進することができます。
44.OUActionNOoiseクラスを作成する
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 44.OUActionNOoiseクラスを作成する class OUActionNoise(object): def __init__(self, mu, sigma=0.15, theta=0.2, dt=1e-2, x0=None): self.mu = mu self.sigma = sigma self.theta = theta self.dt = dt self.x0 = x0 self.reset() def __call__(self): x = self.x_prev + self.theta * (self.mu - self.x_prev) * self.dt + \ self.sigma * np.sqrt(self.dt) * np.random.normal(size=self.mu.shape) self.x_prev = x return x def reset(self): self.x_prev = self.x0 if self.x0 is not None else np.zeros_like(self.mu) |
AgentDDPGクラスに追加
|
1 2 |
# 45.行動ノイズのインスタンス化 self.noise = OUActionNoise(mu=np.zeros(n_action_space)) |
choose_actionメソド内でactionにノイズを入れる。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def choose_action(self, obs): #print('AgentDDPG.choose_action is working.') # 4.方策(アクター)はニューラルネットワークで表現する。 # ActorNNクラスを新規作成し、インスタンスactorとして使用する。 action = self.actor.forward(obs) # 46.行動ノイズを入れて探索性を向上させる。 action += T.tensor(self.noise(), dtype=T.float32) action = action.detach().numpy() return action |
actorにしろcriticにしろ、常にtargetが動いているのでlossが小さくなるわけではないのかなと思い始めました。
前にぴょんぴょん跳ねるような動作が生まれてきました。ノイズのおかげでしょうか。
Keita N
最新記事 by Keita N (全て見る)
- 2024/1/13 ビットコインETFの取引開始:新たな時代の幕開け - 2024年1月13日
- 2024/1/5 日本ビジネスにおける変革の必要性とその方向性 - 2024年1月6日
- 2024/1/3 アメリカ債権ETFの見通しと最新動向 - 2024年1月3日