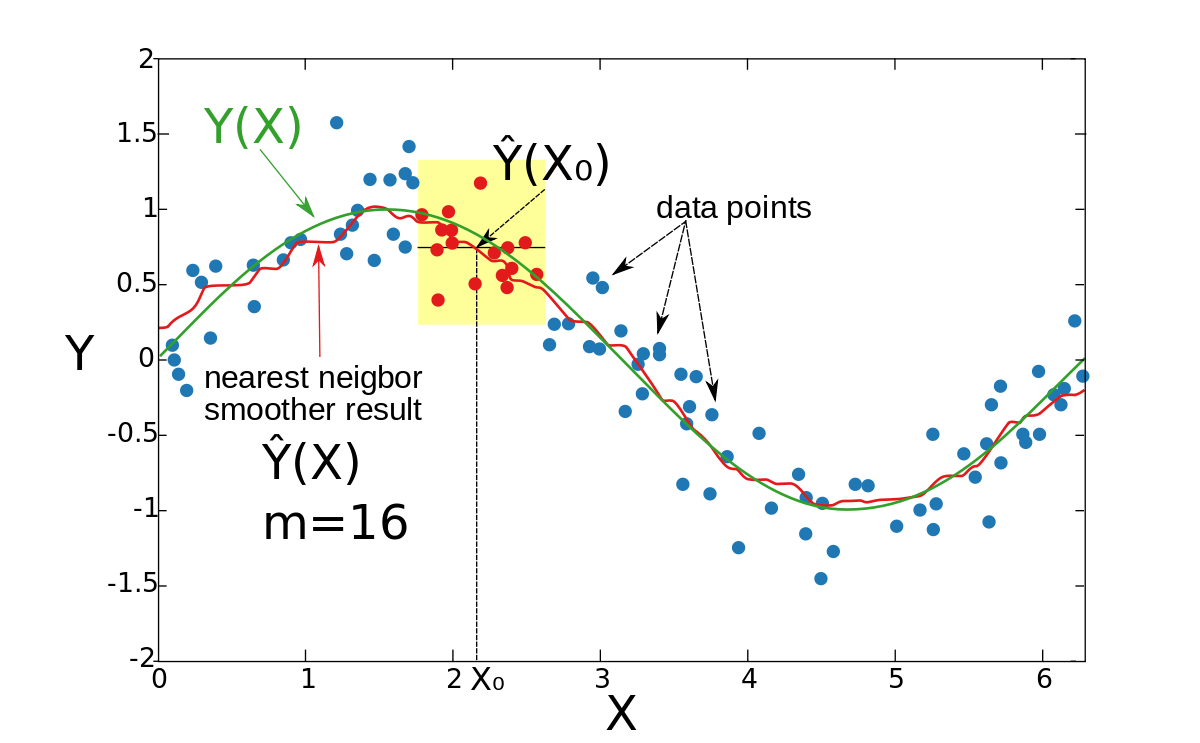
Keita_Nakamoriです。
今回は、ボストンの住宅のデータを眺めて行こうと思います。
ついでにKNNの回帰を試していこうと思います。(前回はKNNの分類でした)
モジュール
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
#ボストンデータ %matplotlib inline #今回はインポートするための処理時間を計測しています import time start_time=time.time() #必要なモジュール群 import numpy as np import pandas as pd import sklearn import matplotlib.pyplot as plt import mglearn end_time=time.time() erapsed_time=end_time-start_time print("処理時間 : ",erapsed_time) #0.6951429843902588 |
ボストンデータをロード
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#ボストンデータをロードしましょう from sklearn.datasets import load_boston #ボストンデータのインスタンスを作成しましょう boston=load_boston() #キーを確認しましょう boston.keys() """ dict_keys(['data', 'target', 'feature_names', 'DESCR']) """ # |
どういうことに使えるでしょうか?
- このデータから回帰を行う(学習する)
- 以降、”特徴量を持つ新規データ”が入ってきたら、その住宅の価格を予測する。理論価格と呼ぶ
- 理論価格より、新規データの価格が10%安ければ買いの判断をする
どんな機械学習アルゴリズムが良いでしょうか
多次元の回帰系ですから、KNN-Regressorをやってみましょう。 だめだったら他のやつを探してみます。
- data とtargetの形を確認しましょう
- 訓練用データと検証用データに分割しましょう
|
1 2 3 4 5 6 7 |
#data とtargetの形を確認しましょう boston["data"].shape #(506, 13) 506データ 特徴量13 boston["target"].shape #(506,) 506データ #訓練用データと検証用データに分割しましょう from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test=train_test_split(boston["data"],boston["target"],random_state=0) |
特徴量について featrue_namesを確認しましょう
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
boston["feature_names"] """ array(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT'], dtype='<U7') """ #feature_namesの記号の意味がわからないので、詳細を確認しましょう print(boston["DESCR"],"\n") """ # boston["DESCR"]だけをprintすると、文字列の羅列が出力されます。 #文字列の中に、改行と思われる"\n"があるので、 print文の引数に"\n"をいれるとテキストが整列されて見やすくなります。 以下は、英語で出力された属性情報をgoogle翻訳にべたばりして日本語化したものです。 だたい言いたいことは分かります。 :属性情報(順): - 町ごとの一人当たりの犯罪率 - 住宅地のZN比率が25,000平方フィートを超える敷地に区画されている。 - 町あたりの非小売業エーカーのINDUS比率 - CHAS Charles Riverダミー変数(トラクトが川の境界にある場合は1、それ以外の場合は0) - 一酸化窒素濃度(1000万分の1) - 住居ごとのRM平均部屋数 - 1940年以前に建設された所有者居住ユニットのAGE比率 - 5つのボストンの雇用センターまでのDIS加重距離 - ラジアルハイウェイへのアクセス可能性のRAD指数 - 10,000ドルあたりのTAX全額固定資産税率 - 町によるPTRATIO生徒教師比率 - B 1000(Bk - 0.63)^ 2 Bkは町による黒人の割合である - 人口のLSTAT%地位が低い - MEDV 1000ドルでの所有者居住住宅の中央値 """ #targetの数値の意味がわからないので確認しましょう。 """ :Median Value (attribute 14) is usually the target 前述の属性情報における 14番め MEDVがtargetのようです。 - 単位は1000ドル 所有者居住住宅の中央値 なぜ中央値がtargetなのでしょうか。 どうやら、このデータひとつひとつは、特定の住宅のデータではなく、地域ごとのデータのようです。 なので、MEDVも、とある地域の中央値ということなのでしょう。 """ |
英語を日本語へ翻訳する方法
前述のようなドキュメントを調べるとき、対象とする分野、業界の用語が列挙されると、そこそこ英語ができても単語の意味がわかりません。
そんなときは逆にチャンスで、ドキュメントをまるごと、google翻訳にかけると、専門用語を英語と日本語で一気に覚えることができます。
私は常に躊躇することなくgoogle翻訳します。
念の為
#アンパックの順番を良く間違うので念の為確認
|
1 2 3 4 5 6 7 8 9 10 11 12 |
X_train[:1],X_test[:1],y_train[:1],y_test[:1] """ちゃんとあっている (array([[1.9133e-01, 2.2000e+01, 5.8600e+00, 0.0000e+00, 4.3100e-01, 5.6050e+00, 7.0200e+01, 7.9549e+00, 7.0000e+00, 3.3000e+02, 1.9100e+01, 3.8913e+02, 1.8460e+01]]), array([[6.7240e-02, 0.0000e+00, 3.2400e+00, 0.0000e+00, 4.6000e-01, 6.3330e+00, 1.7200e+01, 5.2146e+00, 4.0000e+00, 4.3000e+02, 1.6900e+01, 3.7521e+02, 7.3400e+00]]), array([18.5]), array([22.6])) """ |
#データフレーム化してデータを眺めてみる
|
1 2 3 4 5 |
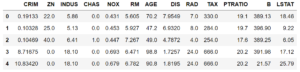
#データフレーム化してデータを眺めてみる columns=boston["feature_names"] #データフレームの列名を定義df=pd.DataFrame(X_train,columns=columns) df=pd.DataFrame(X_train,columns=columns) df[:5] |
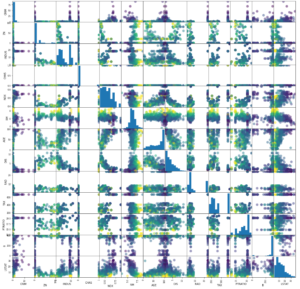
スキャッターマトリクスを眺めてみる
今回もデカイです。
|
1 |
grr=pd.plotting.scatter_matrix(df,c=y_train,figsize=(20,20),marker="o",hist_kwds={"bins":10},s=100,alpha=0.5) |
訓練開始
一瞬過ぎて何事も起こってないようですが、ちゃんと計算できています
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#訓練開始 from sklearn.neighbors import KNeighborsRegressor knn=KNeighborsRegressor(n_neighbors=5) knn """ KNeighborsRegressor(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=5, p=2, weights='uniform') デフォルトでは n_neighbors は5個になっていますね。 """ #機械学習モデルを作成する knn.fit(X_train,y_train) |
予測
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#データを入れて予測をしてみる。 n=len(X_test) prediction=knn.predict(X_test[:n]) """prediction array([20.76, 29.54, 23.08, 11.94, 21.82, 21.4 , 22.96, 24.38, 30.24, 18.26]) """ #生データのtargetを見てみる """y_test[:10] array([22.6, 50. , 23. , 8.3, 21.2, 19.9, 20.6, 18.7, 16.1, 18.6]) """ |
スクリーニングしてみる
|
1 2 3 4 5 6 7 8 9 10 |
#比較してみる y_rate=y_test/prediction y_is_cheaper=y_test[:n]<prediction y_is_05_cheaper=y_test[:n]<prediction*0.95 y_is_10_cheaper=y_test[:n]<prediction*0.90 y_is_20_cheaper=y_test[:n]<prediction*0.80 cheaper_df=pd.DataFrame([prediction,y_test[:n],y_rate,y_is_cheaper,y_is_05_cheaper,y_is_10_cheaper,y_is_20_cheaper], index=["prediction","y_test","y_rate","y is cheaper","5% cheaper","10% cheaper","20% cheaper"]) cheaper_df |

20%以上安い物件の数
22件あるんですね。
この22件について、実際に不動産の知識を持って調査すると良いのではないでしょうか。
|
1 2 3 |
#20%以上安い物件の数 cheap_count=np.sum(y_rate<=0.8,axis=0) print("20%以上安い物件の数 : ",+cheap_count) # 22 |
課題:精度の算出 と 可視化
精度を検証しようとknn.score(X_test,y_test)したところ、0.4616380924610112 と出ましたが、これは一体なんでしょうw
分類と違って、回帰ですから、%ってわけでもないですし・・・ あとで、もう少し考えてみましょう。今は保留。
|
1 2 |
#精度を検証する print(knn.score(X_test,y_test)) |
また、可視化については、回帰ですから、回帰直線みたいなのを引きたいのですが、このような高次元に対しての回帰直線はどのように書いたら良いのでしょうか。今後の課題といたします。
以上、でした。
Keita N
最新記事 by Keita N (全て見る)
- 2024/1/13 ビットコインETFの取引開始:新たな時代の幕開け - 2024年1月13日
- 2024/1/5 日本ビジネスにおける変革の必要性とその方向性 - 2024年1月6日
- 2024/1/3 アメリカ債権ETFの見通しと最新動向 - 2024年1月3日