Keita_Nakamoriです。
前回、アイリスデータの内容を確認しました。
今回は、機械学習で最も単純と思われるk-最近傍法をやっていきます。
- 必要なモジュールをインポート
- データをロードして、入力データと出力データを定義
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
%matplotlib inline from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import numpy as np import pandas as pd import matplotlib.pyplot as plt import mglearn #データをロードする iris_dataset=load_iris() #データのキーを確認する iris_dataset.keys() #dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names']) #入力データと出力データを定義する X=iris_dataset["data"] # as input y=iris_dataset["target"] # as output |
トレインデータ(訓練用)とテストデータ(検証用)に分割する
|
1 |
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0) |
X_train のデータをデータフレーム化して、内容を確認する
columns=iris_dataset[“feature_names”] #データフレームの列名を定義
df=pd.DataFrame(X_train,columns=columns)
df[:5]

X_train のデータフレームをpd.plotting.scatter_matrix()で可視化して眺める。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
grr=pd.plotting.scatter_matrix(df,c=y_train,figsize=(15,15),marker="o",hist_kwds={"bins":10},s=100,alpha=0.5,cmap=mglearn.cm3) """pd.plotting.scatter_matrix()の引数を説明する df : データフレームを入れるだけで、各列同士(4列)を組み合わせた2次元グラフを、 総当たり戦で自動的に作図してくれる。(度数分布 と 2次元散布図) c=y_train : y_trainは 0,1,2 のどれかの値ということを利用して、 プロットのcolorを区別した。 figsize=(15,15):グラフのサイズを大きくする。 marker="o" : マーカー形状を " o " にする。 hist_kwds={"bins":10} : 度数分布の表示をバーチャート、階級数を10とする。 S=100 :プロットのサイズ alpha=0.5 : プロットの透明度 cmap=mglearn.cm3 :配色の設定(なくても問題ないが慣例的につけている) """ |
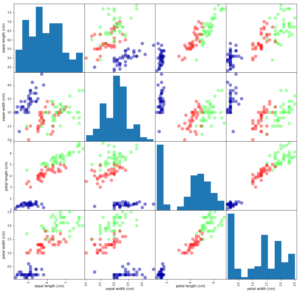
k- 最近傍法分類 をやってみる
モデルの作成とトレーニング
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from sklearn.neighbors import KNeighborsClassifier knn=KNeighborsClassifier(n_neighbors=1) #機械学習モデルを作成する knn.fit(X_train,y_train) """機械学習モデル output KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=1, p=2, weights='uniform') """ |
予測する
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# お試しで新規データを学習済みモデルにinputする X_new=np.array([[5,2.9,1,0.2]]) # sklearnの入力データの仕様としてnumpyの2次元配列にすることになっている。 #予測する prediction=knn.predict(X_new) print("Predicted target name is {} .".format(iris_dataset["target_names"][prediction])) """output Predicted target name is ['setosa'] . """ |
予測性能の評価
|
1 2 3 4 5 6 7 8 9 |
#検証データをすべて学習済みモデルにinputし予測結果を得る y_pred=knn.predict(X_test) """y_pred array([2, 1, 0, 2, 0, 2, 0, 1, 1, 1, 2, 1, 1, 1, 1, 0, 1, 1, 0, 0, 2, 1, 0, 0, 2, 0, 0, 1, 1, 0, 2, 1, 0, 2, 2, 1, 0, 2]) """ |
|
1 2 |
#正解率を算出する np.mean(y_pred==y_test) |
結果:0.9736842105263158
または、
|
1 2 3 4 5 6 7 |
#正解率を算出する 他の方法 knn.score(X_test,y_test) """ この場合、正解率を算出するために、個別の予測結果であるknn.predict()をやる必要はない。 """ |
でもいいです。
The following two tabs change content below.

Keita N
最新記事 by Keita N (全て見る)
- 2024/1/13 ビットコインETFの取引開始:新たな時代の幕開け - 2024年1月13日
- 2024/1/5 日本ビジネスにおける変革の必要性とその方向性 - 2024年1月6日
- 2024/1/3 アメリカ債権ETFの見通しと最新動向 - 2024年1月3日