前回、pandas_datareaderで株価を取得してpandasで統計処理してmatplotlibで可視化するということをやりました。
今回は機械学習をやっていきましょう。
Contents
理屈:
ある1日の株価データのうち、High Low Open Close Volume AdjClose の6データと、さらにOpen Close から算出されるエンジニアリングデータ change を含めて、計7つのデータを入力データとします。(ここまでは前回の話)
その正解データとして、30日後の終値Closeを定義します。
数学モデルは線形回帰モデルを使います。複数の入力データがあるので重回帰分析と呼ばれています。
- y : 正解データ
- x1~x7:入力データ
- a1~a7:回帰パラメータ 偏回帰係数とも呼ばれます
- error:入力データと正解データの差(誤差) 数学モデル上では切片に相当します
y = (a1*x1) + (a2*x2) + (a3*x3) + (a4*x4) + (a5*x5) + (a6*x6) + (a7*x7) + ierror
たくさんの入力データ(1日1データ)をこのモデルに入力して、正解データと入力データの Σ(ai*xi) の部分との差 errorがトータルでできるだけ小さくなるように、最小二乗法を使って ai を決めていきます。
その結果、予測モデルが確定しますので、30日前から現在までの入力データを代入すれば、それぞれの日に対して30日後の終値が予測されます。
# 終値を30日間前にずらしたcolumnを作成します。
ずらされた部分はNaNという値なしの状態で埋められます。
|
1 2 3 |
# 機械学習 df_nvda["label"] = df_nvda["Close"].shift(-30) #30日間過去にずらした。 df_nvda.tail(35) |
# 入力データを作成します
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 入力データを作成する # labelとSMA列は除外して High Low Open Close Volume AdjClose change の計7列を使用する X = np.array(df_nvda.drop(["label","SMA"],axis=1)) X.shape # (1172, 7) # 入力データはスケーリングする(平均を引いて標準偏差で割る) X = sklearn.preprocessing.scale(X) # 30日前から現在までのデータを予測に使用する入力データとして定義 predict_data = X[ -30 : ] predict_data.shape # (30, 7) # 直近30日間を除外した入力データ X = X[ : -30] X.shape #(1142, 7) |
# 正解データを定義します
|
1 2 3 4 5 6 7 8 9 10 |
# 正解データを定義 :30日後の終値のこと y = np.array(df_nvda["label"]) y.shape #(1172,) # 正解データのない部分を削除 y = y[ : -30] y.shape #(1142,) plt.plot(y) |
# データを訓練用と検証用に分割して、学習モデルを選択して、学習させて、検証します
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# データを訓練用と検証用に分割する X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y, test_size = 0.2) # 学習モデルを定義する(インスタンスの作成) lr = sklearn.linear_model.LinearRegression() # 学習する(fitメソド実行) lr.fit(X_train, y_train) #検証する accuracy = lr.score(X_test, y_test) accuracy # 0.9232607206984768 |
# 過去30日間の入力データ predict_data から、それぞれ30日後の未来終値データ predicted_dataを予測します。
|
1 2 3 4 5 |
# 過去30日間の入力データ predict_data から、 # それぞれ30日後の未来終値データ predicted_dataを予測する predicted_data=lr.predict(predict_data) predicted_data.shape # (30,) predicted_data |
# 可視化:予測結果
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
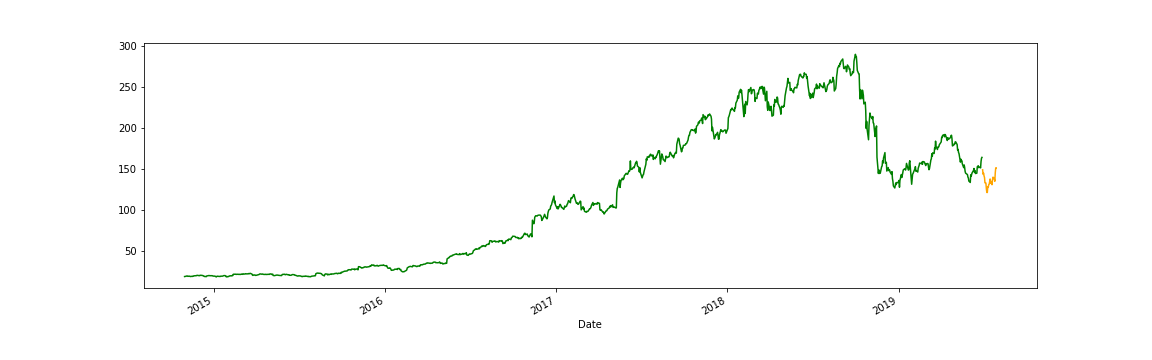
# 予測済みデータをデータフレームに追加するため、 # 予め、空データを入れておく df_nvda["Predicted"] = np.nan # 最終日indexを取得する last_date = df_nvda.iloc[-1].name # Timestamp('2019-09-27 03:00:00') # 1日の数値を定義(決まっている) one_day = 86400 # 最終日に1日足す next_unix = last_date.timestamp() + one_day # 予測済みデータ for data in predicted_data: # 日付を定義 next_date=datetime.datetime.fromtimestamp(next_unix) # 1日カウントアップ next_unix += one_day # index(未来の日付)に予測終値を追加していく df_nvda.loc[next_date] = np.append([np.nan]*(len(df_nvda.columns)-1),data) # 可視化:終値と予測終値 df_nvda["Close"].plot(figsize=(16,5),color="green") df_nvda["Predicted"].plot(figsize=(16,5),color="orange") # fig 保存 plt.savefig("predict_result.png") plt.show() last_date #Timestamp('2019-06-28 00:00:00') |
後ろの黄色いやつが未来の30日間の株価予想です。
Linear Regression でも まあまあそれっぽい答えは帰ってきますね。
The following two tabs change content below.

Keita N
最新記事 by Keita N (全て見る)
- 2024/1/13 ビットコインETFの取引開始:新たな時代の幕開け - 2024年1月13日
- 2024/1/5 日本ビジネスにおける変革の必要性とその方向性 - 2024年1月6日
- 2024/1/3 アメリカ債権ETFの見通しと最新動向 - 2024年1月3日