こんにちは、Keita_Nakamori(´・ω・`)です。
webアプリというものを少し作ってみたいと思います。
- 言語 :Python
- 機械学習 :TensorFlow
- フレームワーク:Django
- データベース : MySQL
- サーバー :Xserver
あたりを使っていきます。
Contents
Anacondaのインストール
Anaconda 2019.07 for Windows Installerをインストールしました。
PathとRegister 両方ともチェックをいれました。
仮想環境djangoaiを作って、ついでにtensorflowを入れます。
Anaconda プロンプトを開いて、
(base) C:\Users\keita>conda create -n djangoai tensorflow
-nってなんでしょう。
# To activate this environment, use
#
# $ conda activate djangoai
#
# To deactivate an active environment, use
#
# $ conda deactivate
ということなので、
$ conda activate djangoai
して使ってみます。モジュール群を確認してみましょう。
(djangoai) C:\Users\keita>pip list
Package Version
——————– ———
absl-py 0.7.1
astor 0.8.0
certifi 2019.6.16
gast 0.2.2
grpcio 1.16.1
h5py 2.9.0
Keras-Applications 1.0.8
Keras-Preprocessing 1.1.0
Markdown 3.1.1
mkl-fft 1.0.14
mkl-random 1.0.2
mkl-service 2.3.0
numpy 1.16.5
pip 19.2.2
protobuf 3.8.0
pyreadline 2.1
scipy 1.3.1
setuptools 41.0.1
six 1.12.0
tensorboard 1.14.0
tensorflow 1.14.0
tensorflow-estimator 1.14.0
termcolor 1.1.0
Werkzeug 0.15.5
wheel 0.33.4
wincertstore 0.2
wrapt 1.11.2
確かにtensorflow 1.14.0が入っていますね。OKです。
Kerasも自動的に入ってきていますね。
仮想環境を抜けましょう。
(djangoai) C:\Users\keita>conda deactivate
(base) C:\Users\keita>
頭の(djangoai)が(base)に切り替わり仮想環境を抜けたことがわかります。
次に、Anaconda Navigatorを使ってみます。
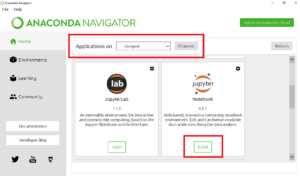
Anaconda Navigatorを立ち上げて、Application on (base)にの部分をdjangoaiに切り替えます。このときまだJupyter NotebookはインストールされていませんのでInstallボタンを押します。完了したらLaunchにボタンが変わりますのでLaunchします。
これでいつものJupyter Notebookが起動しますが。
今回作っていくdjangoaiアプリはユーザーフォルダkeitaの下にanaconda_projectフォルダを作って、その下djangoaiフォルダを作って、その中にスクリプトを入れていきます。
では、Jupyter Notebookを起動したらanaconda_project > djangoフォルダに移動して新規にNewボタン > Python3 しましょう。
TensorFlowの試運転
初心者向けのテストスクリプトがありましたので、実行してみます。
サンプルデータを取得します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import tensorflow as tf # サンプルデータとしてmnistのデータをダウンロード mnist = tf.keras.datasets.mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() # 入力データの形を確認する print(x_train.shape) # (60000, 28, 28) ''' 60000データあってそれぞれが (28行x28列)の数字画像データ ''' # 1つのデータを見てみる print(x_train[0].shape) # (28, 28) print(x_train[0]) # 0から255までの数字が入っている。 # 正解データの形を確認する print(y_train.shape) # (60000,) 60000個の1次元データ print(y_train) # [5 0 4 ... 5 6 8] |
|
1 2 |
# 入力データの数値 0-255 を255で割り算して0-1 に正規化する x_train, x_test = x_train / 255.0, x_test / 255.0 |
機械学習モデルと訓練と評価
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# ニューラルネットワークモデルを作成する model = tf.keras.models.Sequential([ # 入力層の定義:入力データの形を教えて1行にフラット化 tf.keras.layers.Flatten(input_shape=(28, 28)), # 中間層の定義:128ノード 活性化関数はrelu tf.keras.layers.Dense(128, activation='relu'), # データに偏りが発生しないように20%を捨てる tf.keras.layers.Dropout(0.2), # 出力層の定義:0-9の数字を判定したいので10ノード用意する。 # 活性化関数はsoftmax tf.keras.layers.Dense(10, activation='softmax') ]) # 機械学習モデルのコンパイル model.compile(optimizer='adam', #損失関数の定義:最適化(今回は最小化)する対象を定義 loss='sparse_categorical_crossentropy', metrics=['accuracy']) # 訓練する エポック数=5 model.fit(x_train, y_train, epochs=5) ''' Epoch 1/5 60000/60000 [==============================] - 4s 68us/sample - loss: 0.2970 - acc: 0.9146 Epoch 2/5 60000/60000 [==============================] - 4s 65us/sample - loss: 0.1440 - acc: 0.9567 Epoch 3/5 60000/60000 [==============================] - 4s 75us/sample - loss: 0.1077 - acc: 0.9667 Epoch 4/5 60000/60000 [==============================] - 5s 84us/sample - loss: 0.0884 - acc: 0.9731 Epoch 5/5 60000/60000 [==============================] - 4s 74us/sample - loss: 0.0747 - acc: 0.9768 10000/10000 [==============================] - 0s 41us/sample - loss: 0.0709 - acc: 0.9780 ''' # 評価する model.evaluate(x_test, y_test) ''' 損失と精度 [0.07094512566379271, 0.978] ''' |
次回予告
Web Application: 第2回 はじめてのwebアプリ
Keita N
最新記事 by Keita N (全て見る)
- 2024/1/13 ビットコインETFの取引開始:新たな時代の幕開け - 2024年1月13日
- 2024/1/5 日本ビジネスにおける変革の必要性とその方向性 - 2024年1月6日
- 2024/1/3 アメリカ債権ETFの見通しと最新動向 - 2024年1月3日