Contents
クラスタリング
正解データが欠落してる状態を想像してください。
データたちをクラスター(かたまり)として自動的に分類していく作業です。
正解データがないので「教師なし学習」に分類されます。
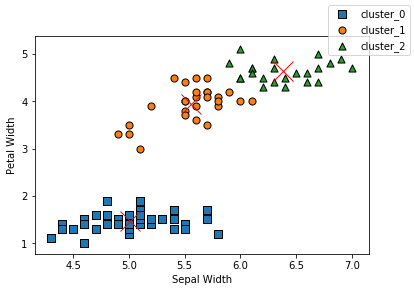
サンプルデータを用意します
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# k-means クラスタリング from sklearn.datasets import load_iris iris = load_iris() iris.keys() #dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename']) # 100データ 2次元(1列目と3列目)を使用する X=iris.data[:100,[0,2]] # 可視化 import matplotlib.pyplot as plt fig, ax = plt.subplots() ax.scatter(X[:,0], X[:,1]) |
k-means クラスタリングをします
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# クラスタリングする from sklearn.cluster import KMeans # K-means のインスタンスを作成する クラスタ数=3 km = KMeans(n_clusters=3, init='random', n_init=10, random_state=0) #訓練と予測をする y_km = km.fit_predict(X) y_km ''' array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 2, 2, 1, 2, 1, 2, 1, 2, 1, 1, 1, 1, 2, 1, 2, 1, 1, 2, 1, 2, 1, 2, 2, 2, 2, 2, 2, 2, 1, 1, 1, 1, 2, 1, 2, 2, 2, 1, 1, 1, 2, 1, 1, 1, 1, 1, 2, 1, 1]) ''' |
プロットします
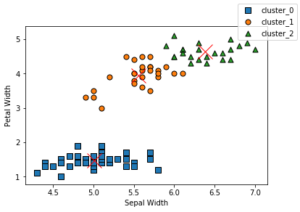
というふうにやります。
The following two tabs change content below.

Keita N
最新記事 by Keita N (全て見る)
- 2024/1/13 ビットコインETFの取引開始:新たな時代の幕開け - 2024年1月13日
- 2024/1/5 日本ビジネスにおける変革の必要性とその方向性 - 2024年1月6日
- 2024/1/3 アメリカ債権ETFの見通しと最新動向 - 2024年1月3日